
Data page — the molecule of Db2 LUW
Db2 came to my life 4 years ago. After few months I was able to use it, more-less. Then I learned how to solve common Db2 issues and how to administer Db2 databases. Recently, when I was thinking about the next topic I could present at 2024’s Db2 conferences, I thought: “What would I like to hear about?”. I realised that the physical side of Db2 still remained kind of a mystery to me. Although I knew what Db2 LUW is made for and how to manage it, I didn’t know what is it made of. I was wandering: “What if I put my Db2 LUW database under a microscope? What would I see? What’s the smallest identifiable unit, into which the database can be divided?”
Peeking into the data page
Let’s check it. To do so, I am going to create a table with one simple row. I am going to use an SMS tablespace, because in such case my table will be manifested by a simple file — this was the default physical architecture in the past, but due to performance needs, IBM made the tablespace topic much more complicated (I will explain this topic exhaustively in a separate post).
So, at first I am creating a table (with one column) called “CURIOUS”.

I am already in the directory that should contain the file that represents the newly created table. Let’s check if there is some newly created file here (it’s April 17th when I am writing these words):

There it is! The filename suggests, the table ID equals 6. Let’s make sure it’s my table:
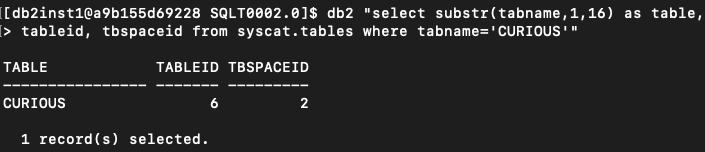
Great! So, what’s inside “SQL00006.DAT”?

Hmm… it doesn't seem to be readable by a human. This means that you cannot just take a piece of a Db2 database and read it without any tools. Luckily, Db2 offers a tool that will help me peek inside the file (which is the physical manifesto of my table), namely db2dart (you must deactivate your database before running db2dart):
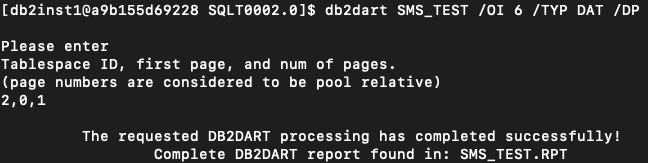
/OI means ‘object ID’ — this is the ‘TABLEID’ from the screenshot above. /TYP is the type of the object (data). /DP stands for ‘dump pages’, which lets me see my data in hex format. Then I am requested for tablespace ID (also in the screenshot above) and pages I want to check (my table is empty, so it fits in just one page).
What’s inside the report (SMS_TEST.RPT)? Among others, there is the hex dump of my table. Below is the beginning of the page:
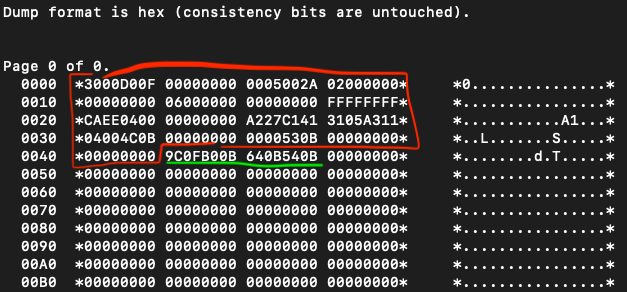
What’s exactly in the screenshot? In the left column, there is the offset (in bytes) from the beginning of the page in hexadecimal format (I call it an address as well). Then, between asterisks (‘*’) there are values of these bytes (each byte is represented by 2 characters: ‘30’, ‘00’, ‘D0’ etc.). There are 16 bytes in one row. And in the column on the right side (also between ‘*’) there are these values in human readable format (don’t focus on them for now).
Although the table is empty, you can see some data from byte no. 0000 till byte no 004A (the numbering is in hexadecimal format — 16-based). Data until 0043 is the page’s header (marked with a red colour). The next 8 bytes (till 004A) represent the slot directory (highlighted by a green line; more about the slot directory in a minute).
IBM doesn’t share much information about headers, however I found out that two first bytes describe the operating system the database resides on — ‘3000’ means Unix little-endian (this information will be useful later in this article). Headers don’t keep your data, they keep some Db2's metadata.

There is also some data at the end of the page starting from 0B9A. This information is related to the table’s type, table’s header and so on. It resides only on the first data page and I will not discuss it in detail today.
Ok, let’s insert something to the CURIOUS table. Right now, it is empty:

Adding a row
Now, let’s add the first row to my table called, surprisingly, “firstROW”…
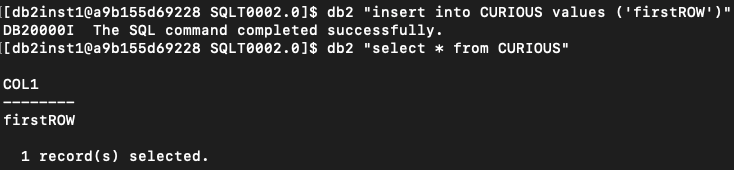
…and do the db2dart magic again:
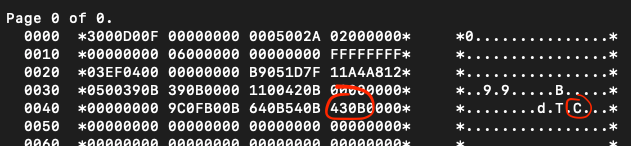

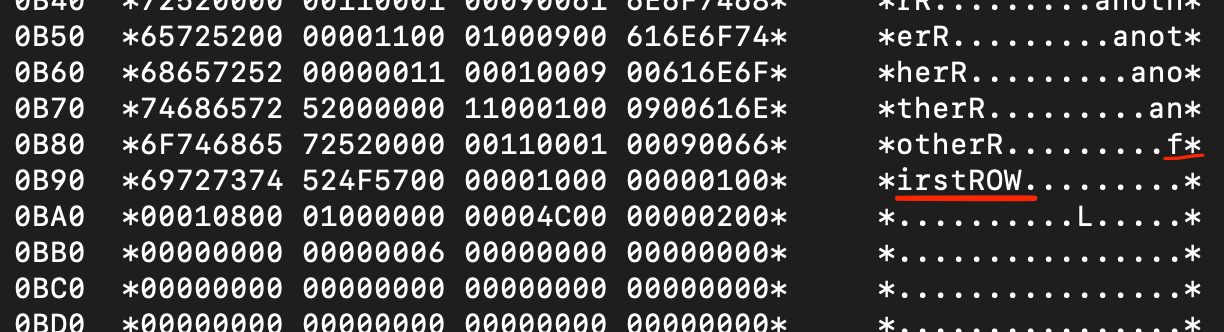
As you can see, there are two new bytes (‘430B’) right after the header and around 16 new bytes just before the ‘tail’ of the page. And look! On the right, there is my ‘firstROW’ I added!
Data page structure
OK, so why the ‘firstROW’ string of mine exists at the end and what that ‘430B’ value is doing right after the page header? Let’s look at the example below. It shows the structure of a sample data page (I downloaded this picture from the best Db2 blog in the world, link)

As you already know, the page starts with a page header that keeps some metadata. Then, in the picture you can see ‘3790’, ‘-1’, ‘3390’… — this is the slot directory (as you may recall). Each slot (unless it equals -1) represents an offset between the end of the header and a record in the page. First offset (3790) stands for the first row, second — for the second row, and so on. ‘-1’ means that the record doesn’t exist anymore (it has been deleted leaving some “embedded free space”). The cells in the picture are coloured, so that you can see which record is linked to which slot. These offsets appear in the decreasing order, because the rows are written to the page starting starting from the end. Why? When the consecutive records are being added, Db2 doesn’t know how many records will fit in the page, which means it doesn’t know, where the slot directory will end, so it wouldn’t know, where the space for records should start.
To sum up, a standard data page is made of 3 parts:
- the header that contains Db2 meta-data;
- the slot directory that is list of pointers to the records stored in the data page, where each slot:
- represents 1 record (row),
- occupies 2 bytes,
- stores the offset between the end of the header and the beginning of the record it represents; - records themselves, which represent rows of the table.
Let’s go back to our CURIOUS table and its hex dump:
Number ‘430B’ appeared, when I added a row into the table. This is the first record in the slot directory. It points to the first row in the page that starts at address 0B87.
You may wonder how the ‘430B’ could point to 0B87. If you’re an observant person, you may notice that byte ‘0B’ appears in both numbers and it also appears in other slots (‘540B’, ‘640B’, ‘B00B’ and so on). In my case it took me hours to notice that, but it was a breakthrough, because it let me realise the bytes in these 2-byte values are swapped! And this is how it is in the little-endian operating systems like Red Hat Linux I use. This ‘little-endianness’ is marked in the first 2 bytes of each data page (namely ‘3000’; in case of big-endian it would be ‘0030’ and bytes would not be swapped). So, I need to swap back the bytes of the slot related to the ‘firstROW’, which gives me ‘0B43’. This is much closer to the address of the first record, which is ‘0B87’! The difference between these two values equals 0x44 (‘0x’ means that the number is in hexadecimal format). And 0x44 is the number of bytes that make up the page’s header (as you may remember, headers reside on addresses from 0000 till 0043)! So, we have a proof that the value in the slot is the offset between the end of the header and the address of the record in the data page.
Adding more rows
OK, let’s do more! What if I add 1000 more rows into the CURIOUS table?

After adding 1000 new rows (with a string ‘anotherROW’), let’s db2dart again. Now, beginning of the first page looks like this:
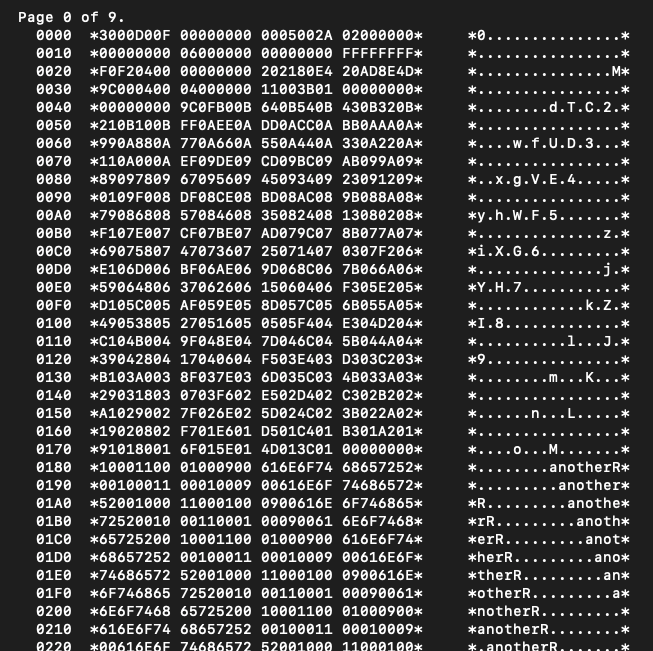
As you see the first page (page 0 of 9) is full. At address 017B ends the slot directory and at address 0180 starts the last record on this page (last in table’s order). The space before the ‘tail’ on the first page is below:

As you see, the last record in the screenshot is the first record in the table (‘firstROW’).
The second page begins as follows:
And ends like this (notice that there is no ‘tail’ in this case):
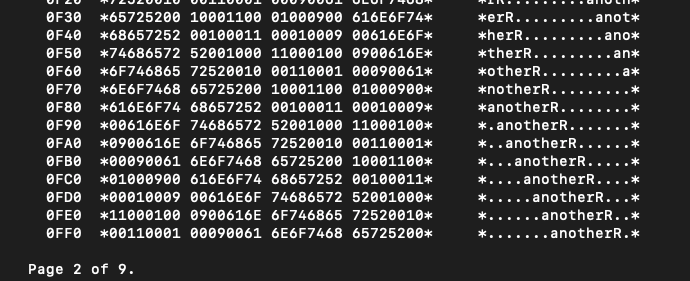
The last non-empty page is the sixth page (page no. 5) Below is the beginning and the end, respectively:
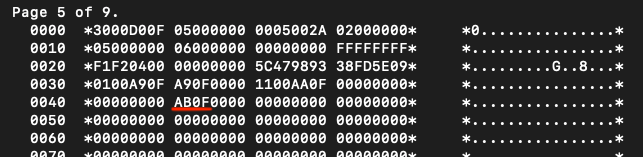
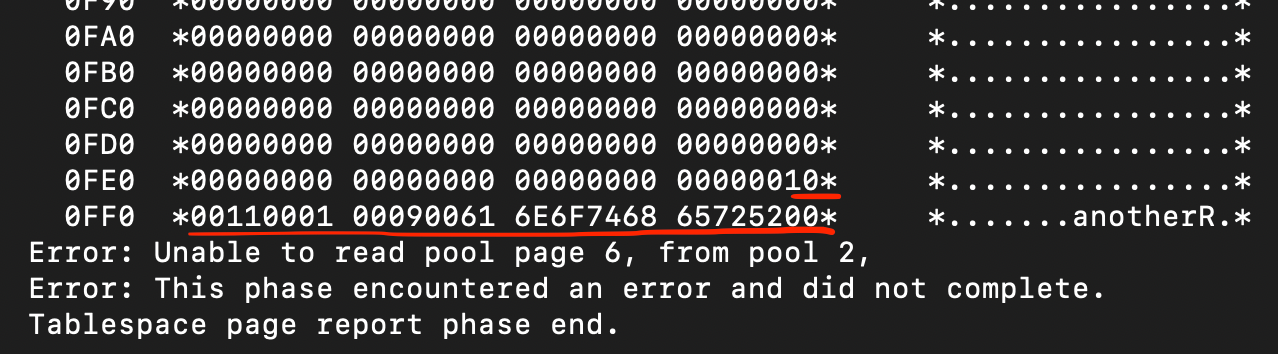
As you can see, the first two bytes after the header (page 5 of 9) reside at addresses 0044–0045 and equal AB0F. After I swap these bytes I get ‘0FAB’. It should be the offset between 0044 (end of the header) and the first (and the only one on this page) record’s position. 0FAB + 0044 equals 0FEF. Under that address I see byte ‘10’, which is indeed the beginning of the record. It works! Notice that the first record is written just at the end of the data page!
Deleting a row
Last thing. Let’s delete a row:
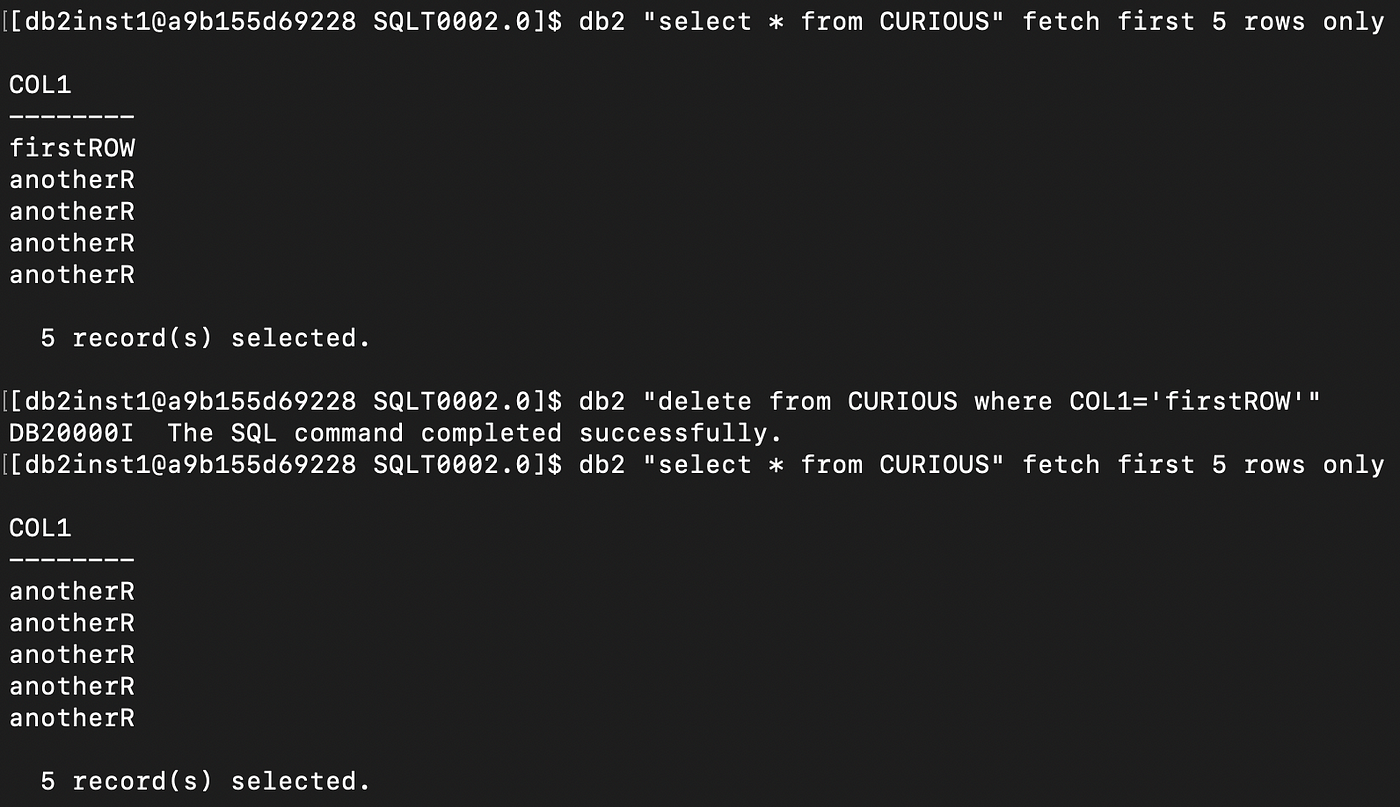
How does the hex dump of the first data page look like now?
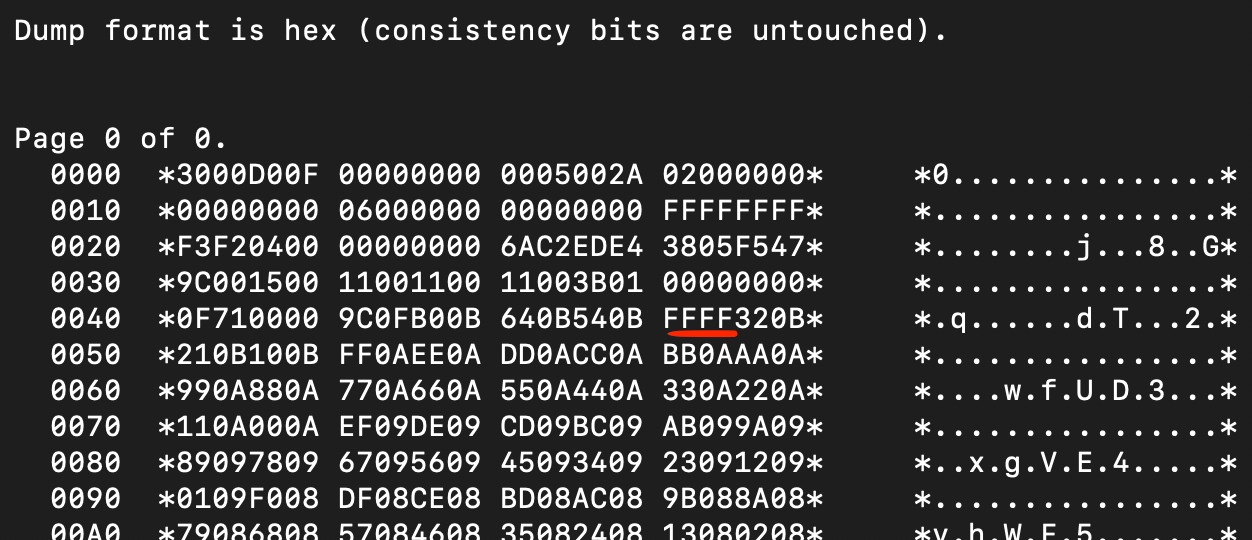
As you can see at the address of the first record’s slot (firstROW’s slot), namely ‘004C’, where previously there was value ‘430B’, now there is ‘FFFF’. But wait… I told you that after a row is deleted, its slot equals ‘-1'… The thing is that these slots cannot take negative values, therefore when you subtract 1 from 0000, you receive the largest possible value, which is ‘FFFF’. The biggest possible offset is well below ‘FFFF’, therefore Db2 knows that ‘FFFF’ should be interpreted as a deleted row, not an offset.
And what about the record itself? It’s still there! The reason for that is that Db2 only marked a row as deleted (by changing the slot’s value). It’s faster and less costly (I mean CPU and memory cost) — maybe in this case it wouldn’t matter, but it does matter if I deleted thousands of rows.
Reorging the table
But, if the rows are only marked as deleted, they still use my disk space… What if I want to free unused space in my data pages? Do the REORG:

Let’s db2dart for the last time and check what happened after I REORGed my table.

There is no ‘FFFF’! So, there are no rows marked as deleted now. Let’s scroll down the db2dart report…

See? No sign of the ‘firstROW’. It’s permanently deleted and all the records are moved on the page a little bit (and the table should fit in 5 pages instead of 6). In the table and on the page, the second record becomes the first, the 3rd becomes the 2nd and so on. But remember that although I reclaimed some disk space, such an operation is costly. Therefore it’s not done immediately after delete. REORGs are usually performed, when there is little traffic on the database, e.g. at night, when few clients are connected to the database server.
Now, after all of these microscope (db2dart) checks made after each simple change on my table, I feel like Db2 is a bit more transparent to me. I know that, even though it was much work, I still have a long way to learn all the secrets. But maybe this is good news. I really like it, when the technology I use, reveals its secrets to me.